
AI News: Cerebras WSE-3 $CBRS $NVDA
The 4-Trillion-Transistor Wafer-Scale Monster Redefining What a Single Semiconductor Can Do
By Shayne Heffernan
In the high-stakes race to build ever-more-powerful AI hardware, most companies are playing the same game: shrink transistors, stack more dies, add faster memory, and interconnect thousands of chips with ever-more-complex networking fabric. $CBRS Cerebras Systems took one look at that playbook and threw it in the trash.
Instead, the Sunnyvale-based company asked a radical question: What if we stopped cutting the wafer into tiny rectangles and just used the entire 300mm silicon wafer as one single, monolithic processor?
The answer is the Cerebras Wafer Scale Engine 3 (WSE-3) — currently the most powerful semiconductor in development on the planet. With 4 trillion transistors, 900,000 AI-optimized cores, 125 petaflops of peak AI performance, and 44 gigabytes of on-chip SRAM, the WSE-3 is not a chip. It is an entire silicon dinner plate turned into a single processor. Its die area measures a staggering 46,225 mm² — 57 times larger than $NVDA Nvidia’s H100 GPU.
This is not hype. It is engineering at the absolute edge of what physics and TSMC’s 5nm process will currently allow. And while Nvidia’s upcoming Vera Rubin platform will dominate volume deployments in 2026–2027, the WSE-3 remains the undisputed champion when it comes to raw, single-piece-of-silicon computational power.
The Numbers That Break Brains
Let’s start with the raw specifications, because they are almost absurd:
Transistors: 4 trillion (more than 12× Nvidia Blackwell B200)
AI-optimized cores: 900,000 (52× more than H100)
Peak AI performance: 125 petaflops (FP16)
On-chip SRAM: 44 GB (880× more than a single H100)
Memory bandwidth: 21 petabytes per second (7,000× more than H100)
Fabric bandwidth: 214 petabits per second
Process node: TSMC 5nm
Die size: 46,225 mm² (21.5 cm × 21.5 cm)
Each WSE-3 powers a single Cerebras CS-3 system that consumes roughly 23–25 kW of power. Scale that up and a full cluster of 2,048 CS-3 nodes delivers 256 exaflops of AI compute — enough to train models with 24 trillion parameters without the usual distributed-training headaches.
External memory options scale from 1.5 TB all the way to 1.2 petabytes in the hyperscale configuration. That is not a typo. One logical device can hold an entire frontier-model’s worth of weights and activations in a way that traditional GPU clusters can only dream of.
From WSE-1 to WSE-3: A Brief History of Wafer-Scale Insanity
Cerebras did not arrive at the WSE-3 overnight. The company was founded in 2016 with the explicit mission to solve the “memory wall” that has plagued AI training for years. Traditional GPUs are memory-bandwidth starved when dealing with massive models. Data has to constantly shuttle between off-chip HBM and compute cores, creating latency and energy waste.
The first Wafer Scale Engine (WSE-1) arrived in 2019 on TSMC 16nm. It was already monstrous — 1.2 trillion transistors and 400,000 cores. WSE-2 followed in 2021 on 7nm with 2.6 trillion transistors and 850,000 cores. Each generation doubled performance at roughly the same power envelope while moving to newer process nodes.
The WSE-3, unveiled in March 2024 and now in full production deployment, represents the latest leap. Built on 5nm, it delivers roughly 2× the performance of WSE-2 while maintaining the same power draw and price point. The secret sauce is not just density — it is the elimination of almost all inter-die communication.
In a traditional multi-GPU or multi-die system (including Nvidia’s NVLink clusters), data movement between chips is the single biggest bottleneck. Cerebras keeps everything — compute, memory, and interconnect — on one contiguous piece of silicon. The result is near-zero latency and insane effective bandwidth.
Why Wafer-Scale Architecture Is Revolutionary
To understand the advantage, imagine trying to run a trillion-parameter model on a GPU cluster. You must shard the model across hundreds or thousands of GPUs. Every forward and backward pass requires constant synchronization across the network fabric. This creates communication overhead that scales poorly and wastes enormous energy.
The WSE-3 treats the entire wafer as one giant logical core. Entire transformer layers or attention heads can live natively on the silicon without being sliced apart. Memory bandwidth becomes effectively unlimited for the workloads that matter most.
Cerebras claims real-world inference speeds of 2,500–2,700 tokens per second on large models such as Llama 4 Maverick — up to 21× faster than equivalent Nvidia DGX B200 Blackwell systems in head-to-head production tests. Training times for frontier models are similarly compressed because the programming model is dramatically simpler. Developers write code as if the entire supercomputer is one single device.
Power efficiency follows. While a single CS-3 draws 23 kW, its performance-per-watt advantage over GPU clusters is substantial when normalized for the same workload. Independent analyses (including from SemiAnalysis) show 32% lower cost per token and roughly one-third lower energy consumption versus Blackwell equivalents for certain inference tasks.
Head-to-Head: WSE-3 vs. Nvidia’s Rubin Platform
Nvidia’s Vera Rubin GPU (expected in the second half of 2026) remains the practical workhorse of the AI industry. It will ship with approximately 336 billion transistors, 288 GB of HBM4 memory, and strong ecosystem support via CUDA. Hyperscalers and enterprises love it because it is available in volume, well-understood, and integrates seamlessly into existing software stacks.
But raw single-chip power tells a different story:
Metric | Cerebras WSE-3 | Nvidia Vera Rubin (est.) | Clear Winner |
Transistors | 4 trillion | ~336 billion | Cerebras |
AI Cores | 900,000 | ~25,000+ (projected) | Cerebras |
Peak Performance | 125 petaflops | ~50 petaflops (FP4 inference) | Cerebras |
On-Chip SRAM | 44 GB | Lower (HBM dominant) | Cerebras |
Memory Bandwidth | 21 PB/s | ~22 TB/s HBM4 | Cerebras |
Real-World Inference Speed | 21× faster in tested workloads | Strong ecosystem scaling | Cerebras (niche) |
Volume & Availability | Specialized systems | Mass production | Nvidia |
Software Ecosystem | Cerebras-specific | CUDA dominance | Nvidia |
Cerebras wins decisively on monolithic performance and memory-bound workloads. Nvidia wins on everything else: software maturity, supply chain scale, and broad applicability. Most enterprises will continue buying Nvidia racks. The customers who need the absolute fastest single-logical-device performance for the largest models are turning to Cerebras.
Real-World Deployments and Customer Wins
Cerebras is not just shipping prototypes. The company has already built Condor Galaxy supercomputers in partnership with G42 (UAE) that now exceed 16 exaflops total. Condor Galaxy 3, powered by 64 CS-3 systems, delivers 8 exaflops in a single facility. Production customers are running trillion-parameter models at speeds that were considered impossible on GPU clusters just two years ago.
Inference benchmarks on models like Llama 3 70B, GPT-class architectures, and multimodal systems show consistent 10–21× speedups versus equivalent GPU setups. For latency-sensitive applications — real-time reasoning, agentic AI, conversational systems — the advantage is even more pronounced.
The Challenges: Yield, Power, Cooling, and EcosystemNone of this comes without trade-offs. Fabricating a defect-free 46,225 mm² die is extraordinarily difficult. Cerebras has invested heavily in redundancy and fault-tolerant design so that manufacturing defects do not kill the entire wafer. Power delivery is another engineering feat: the WSE-3 requires ~30,000 amps of current managed through advanced 3D power distribution and dense voltage regulators placed directly on the wafer.
Cooling a 25 kW single chip demands liquid or advanced immersion systems. Data-center operators must rethink rack design entirely. And while Cerebras has built a robust software stack (including full PyTorch compatibility and a simplified programming model), it still lacks the decade of ecosystem maturity that CUDA enjoys.
Cost is another factor. Individual CS-3 systems are priced in the $2–3 million range. That is premium territory, but when normalized for performance on the largest models, the total cost of ownership can actually be lower than equivalent GPU clusters.
Market Impact and the Road AheadCerebras went public in 2026 at a valuation that reflected both the hype and the very real technical achievement. The company has proven that wafer-scale integration is not just possible — it is commercially viable for the most demanding AI workloads.
Does this mean Nvidia is in trouble? Not remotely. Nvidia’s ecosystem lock-in, volume manufacturing, and relentless iteration on smaller, more efficient GPUs ensure it will dominate the broad market for years. But Cerebras has carved out a defensible niche at the absolute frontier: the largest models, the highest-throughput inference, and the workloads where memory bandwidth and monolithic compute matter most.
The WSE-3 proves that there is still room for radical architectural innovation in semiconductors. While the rest of the industry doubles down on chiplets, advanced packaging, and 3D stacking, Cerebras doubled down on the simplest possible idea: make the chip as big as physically possible.
As AI models continue scaling toward 10 trillion, 50 trillion, and even larger parameter counts, the memory-wall problem only gets worse. Wafer-scale architectures may not replace GPUs for every use case, but they have established themselves as the gold standard for the most extreme workloads.
The future of AI compute is bifurcating. One path is the highly optimized, massively parallel GPU cluster perfected by Nvidia. The other is the monolithic wafer-scale approach pioneered by Cerebras. Both will coexist — and both will push the boundaries of what artificial intelligence can achieve.
For now, the crown for “most powerful semiconductor in development” belongs unequivocally to the Cerebras WSE-3. It is a dinner-plate-sized slab of silicon that does what thousands of smaller chips struggle to accomplish — and it does it faster, with less complexity, and often at lower effective cost for the hardest problems in AI.
The wafer-scale revolution is no longer theoretical. It is here, it is shipping, and it is redefining the upper limits of what a single piece of silicon can do.— Shayne Heffernan

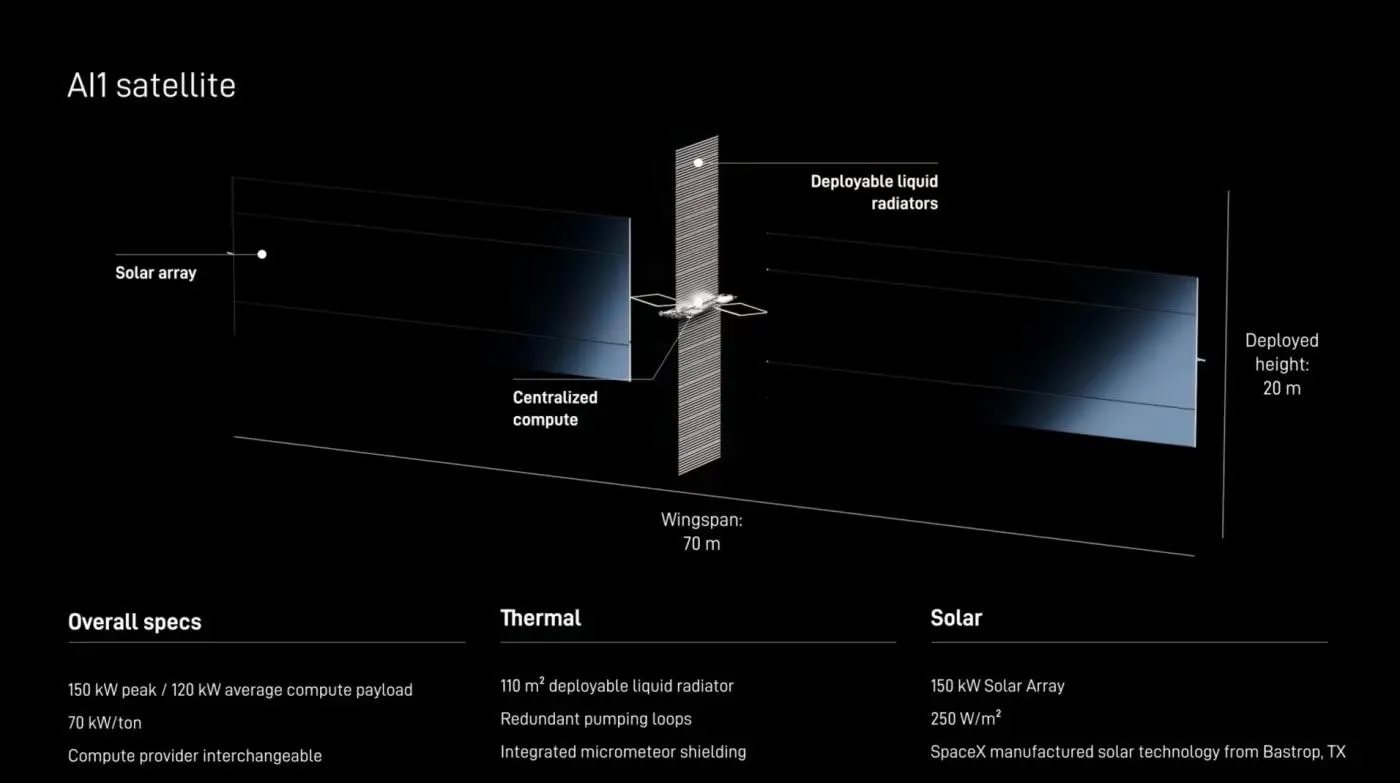
SpaceX’s AI Satellites: Revolution in AI Compute
SpaceX’s AI satellites (SPCX) will deliver massive low-cost orbital compute using Nvidia then custom D3 chips from Terafab, powering xAI/Grok while creating major tailwinds for $TSLA $NVDA $GOOGL and $ANTH.

10 Best Stocks to Buy Right Now in June 2026 – My Current Watchlist
AI spending continues as the dominant long-term theme, but capital is rotating toward companies with strong earnings, reasonable valuations, and real infrastructure exposure.

Quantum AI Is Already Reshaping Markets
I've traded through enough hype to know quantum AI won't flip everything overnight. But the 2026 signals — funding, hybrids in finance, hardware progress — say it's accelerating. The players and platforms that nail security and optimization will carry the edge.

The Compute Market Boom
BlackRock CEO Larry Fink’s recent endorsement of compute as a new asset class, the impending launch of CME compute futures, massive hyperscaler deals such as Google’s $920 million monthly commitment to SpaceX
Every story, signed and delivered.
Subscribe to the kxco channel and get the headline, the AI-written key takeaways, and the chain-anchor link the moment we publish. Audio versions and per-ticker subscriptions arrive in the next iteration.